

MCAP and ROS 1 bag are two broadly-comparable file formats for recording robotics data. Both formats specify a chunked container structure that supports heterogeneously-typed messages and includes a trailing index section to enable summarization.
MCAP’s most publicized advantage over bag files is its support for arbitrary message serialization formats (e.g. Protobuf, FlatBuffers, CDR, etc.), while ROS 1 bags are constrained to messages serialized in the ROS 1 msg format.
In this post, we’ll highlight a less-publicized feature of MCAP over bag files: improvements in the index structure that enable faster summarization over remote connections or slow storage devices.
Summarizing ROS 1 and MCAP files
ROS bags and MCAP files may range from megabytes to hundreds of gigabytes or larger in size. Reading them off disk or across a network can be prohibitively expensive, especially if the goal is just to get a high-level summary of their contents.
The rosbag info and mcap info commands allow you to quickly summarize the contents of a ROS bag or MCAP file, including:
- Topics and message types
- Frequencies and message counts per topic
- Start and end times of messages
- Compression statistics
Comparing summarization performance over remote connections
Bag files and MCAP files are often accessed over remote connections - e.g. sharing recordings with a Network File System (NFS) file share or an Amazon S3 bucket.
Let’s compare the performance of rosbag info and mcap info when reading from local disk vs. over NFS. We’ll use the following bag files for our comparison:
small.bag1- 67.1 MB in size
- 79 chunks, 7 topics
- 1606 messages
large.bag[^2]- 15.7 GB in size
- 9855 chunks, 58 topics
- 5304180 messages
Here are the timings for rosbag info on local disk:
$ time rosbag info small.bag > /dev/null
real 0m0.244s
user 0m0.105s
sys 0m0.042s
$ time rosbag info large.bag > /dev/null
real 0m0.547s
user 0m0.384s
sys 0m0.066sAnd for mcap info, also on local disk:
$ time mcap info small.mcap > /dev/null
real 0m0.011s
user 0m0.006s
sys 0m0.000s
$ time mcap info large.mcap > /dev/null
real 0m0.013s
user 0m0.016s
sys 0m0.000sGoing off the wall clock execution times reported (real in the output), we can see that the mcap info command executes 22x and 42x faster than the rosbag info command. In fact, the MCAP timings are so low that they can be considered mostly noise.
Although this difference is striking, you may intuit that it is partially due to slow startup of rosbag’s Python interpreter.
Below are the same measurements taken over a remote NFS connection (NFS throughput from the server to the client is approximately 64Mbps):
$ time rosbag info small.bag > /dev/null
real 0m8.875s
user 0m0.242s
sys 0m0.061s
$ time rosbag info large.bag > /dev/null
real 13m45.866s
user 0m1.449s
sys 0m3.825s$ time mcap info small.mcap > /dev/null
real 0m0.162s
user 0m0.000s
sys 0m0.016s
$ time mcap info large.mcap > /dev/null
real 0m0.185s
user 0m0.014s
sys 0m0.009sHere, the differences explode to factors of 54x and 4458x. The rosbag info command is slow enough to be unusable over NFS, for both large and small files.
Understanding the performance gap
So why is performance of rosbag info so poor over NFS? And how does mcap info do better?
Let’s use strace to get some clues:
$ strace -c -U calls rosbag info large.bag 2>&1 1>/dev/null
calls syscall
--------- ----------------
40217 lseek
11540 read
<snip>
--------- ----------------
56284 total$ strace -c -U calls mcap info large.mcap 2>&1 1>/dev/null
calls syscall
--------- ------------------
183 read
7 close
6 fstat
2 lseek
<snip>
--------- ------------------
518 totalWe see that rosbag info is doing a dramatically larger number of disk seeks and reads than mcap info.
For another view, let’s compare seek calls for rosbag info vs mcap info as a function of number of chunks in the file.
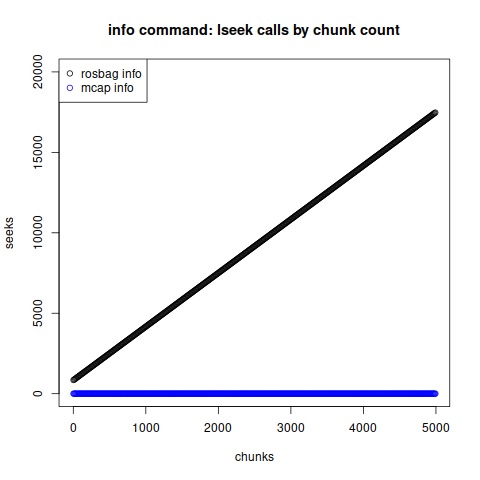
We see that the number of disk seeks executed by rosbag info grows linearly in proportion to the number of chunks in the bag file. Meanwhile, the number of seeks executed by mcap info appears constant.
Excessive seeking and reading from different locations on disk is generally harmful for IO performance:
- For hard disk drives, moving the disk head generally takes at least 5 milliseconds.
- For all devices, reads happen at the granularity of file system pages, which are generally 4kb. Reading less than 4kb of data will still pull 4kb from disk or over a network if using remote storage.
Operating systems mitigate these effects by performing reads through a page cache. If a page is cached, it can be read from memory instead of from disk. However, pages are not cached when reading a file for the first time – in that scenario, disk IO will be required for every read.
So why does rosbag need to do so many seeks? Let’s inspect the rosbag info output for small.bag:
$ rosbag info small.bag
path: small.bag
version: 2.0
duration: 7.8s
start: Mar 21 2017 19:26:20.10 (1490149580.10)
end: Mar 21 2017 19:26:27.88 (1490149587.88)
size: 67.1 MB
messages: 1606
compression: lz4 [79/79 chunks; 56.23%]
uncompressed: 119.1 MB @ 15.3 MB/s
compressed: 67.0 MB @ 8.6 MB/s (56.23%)
types: diagnostic_msgs/DiagnosticArray [60810da900de1dd6ddd437c3503511da]
radar_driver/RadarTracks [6a2de2f790cb8bb0e149d45d297462f8]
sensor_msgs/CompressedImage [8f7a12909da2c9d3332d540a0977563f]
sensor_msgs/PointCloud2 [1158d486dd51d683ce2f1be655c3c181]
sensor_msgs/Range [c005c34273dc426c67a020a87bc24148]
tf2_msgs/TFMessage [94810edda583a504dfda3829e70d7eec]
topics: /diagnostics 52 msgs : diagnostic_msgs/DiagnosticArray
/image_color/compressed 234 msgs : sensor_msgs/CompressedImage
/radar/points 156 msgs : sensor_msgs/PointCloud2
/radar/range 156 msgs : sensor_msgs/Range
/radar/tracks 156 msgs : radar_driver/RadarTracks
/tf 774 msgs : tf2_msgs/TFMessage
/velodyne_points 78 msgs : sensor_msgs/PointCloud2Let’s focus on the compression, uncompressed, and compressed lines. Like MCAP, the bag format uses a two-layer index structure in which the bottom of the file contains an index of chunks, and each chunk is followed by an index of messages within it. But unlike MCAP, the Chunk Info records that make up the chunk index contain no information about compression algorithms or compressed/uncompressed sizes.
To gather compression statistics, rosbag info must visit every chunk in the file to read compression information from the corresponding header. Since ROS bags are commonly recorded with a default chunk size of 768Kb (uncompressed), it does not take a very large bag to accumulate a large number of chunks. On a developer laptop, the effect of this may go largely unnoticed or get attributed to Python startup. But on remote filesystems, you will notice significant degradation for bags larger than a few megabytes, since every chunk will require seeking to and reading an uncached page. The amount of data in a chunk header is small in comparison to a 4kb page, so we’d be significantly overfetching to read a small amount of data.
This problem with rosbag cannot easily be fixed. Solving rosbag info performance would not be technically difficult, but it would require a breaking change: dropping compression statistics from the printed output. Since these statistics are quite useful, this is not so easy. An opt-in flag (i.e “—fast”) could be supported without much trouble, but introducing such functionality as a non-default behavior would still leave many consumers impacted.
Furthermore, the problem extends beyond the rosbag info command: it actually results from the start_reading method, which is called any time a bag file is opened. Bag users will pay this cost every time they open a bag with the Python SDK.
Eliminating the problem with MCAP
Fast remote summarization was one of MCAP’s design goals.
In MCAP, all the data required to summarize the file is present in the summary section, and visiting the data section is never necessary. The mcap info command requires only two seeks: first to the footer, and then to the summary start. After seeking to the summary start, it reads to the end of the file and transforms the summary section into the output that it prints.
Consequently, mcap info’s performance is largely disconnected from the size of the file or the number of chunks. While the volume of data read is still linear with respect to the number of chunks, since there is one Chunk Index record in the summary section per chunk, the contribution of each chunk to the summary section size is negligible. For example, the summary section of large.mcap, a 12GB file, is only 820 kB.
Closing advice
If you’re a new ROS user and looking to choose a data recording format, we recommend adopting ROS 2 to take advantage of MCAP’s performance. MCAP is the default recording format for ROS 2, has superior summarization and SDK performance, and will receive more community development attention going forward.
However, swapping out recording formats on an existing system may be easier said than done. For users unable to switch and struggling with IO performance, consider using skip_index: True in your bag processing scripts. This will bring the cost of opening bags in line with what you get from rosbag info – not ideal, but better than the default behavior of the Bag constructor.
If you have any questions about MCAP, or need support adopting it for your robotics development workflows, feel free to join our Discord community or contact us directly for help.
Footnotes
-
Derived from
NOISY_cut_off_2.bagpublished by Udacity as part of its Didi competition[^2]: Published by Northern Robotics Laboratory at Université Laval asTeachA.bag: https://doi.org/10.55417/fr.2022050 ↩


