Why Building a Working Robot Doesn't Guarantee Commercial Success
The critical role of observability in robotics


There is a transformative shift happening in the robotics industry. A decade ago, autonomous robots were largely confined to the lab, with only a handful of companies successfully deploying them into production. However, recent advancements – like new AI models, cheaper sensors and batteries, and more computing power – have begun introducing autonomous systems to every corner of human life.
But old development practices aren’t equipped to take us into this new era of robotics. It is not enough to get a single robot working - to avoid getting left behind, companies must rapidly scale these prototypes into profitable fleets. This requires incorporating observability at every stage of development, so we can understand how our robots sense, think, and act at scale.

Achieving reliability at scale
While the surge of robots in production is exciting, making them work reliably at scale is an entirely different story.
The economic landscape has shifted – capital costs have risen, funding is increasingly difficult to obtain, and VC firms are demanding to see profitable unit economics before making investments. Most companies that fail to get to production fail for one simple reason – they struggle to make their prototypes work reliably and profitably at scale.

If a robot can work an entire week and encounter a single issue, we used to consider that a win. But as we bring robots to production, the math starts working against us. Our prototype’s weekly issue is actually a huge problem at scale. If we grow our fleet from one robot to 100, we’re seeing a failure every other hour. At this point, we need a large operations team to run around fixing these issues.
During the R&D phase, we can get away with the “get it working once” mentality. We can SSH into individual robots to debug them, and we can treat them like pets – with unique names, settings, and even code versions. But as we scale in production, we need to start thinking about our robots as, well, exactly that – robots, not pets. It simply isn’t sustainable for thousands of devices to each have unique quirks. We need a different approach in order to reason about our robots’ behaviors collectively.
Observability is the key to success
To address these challenges, we need observability. Originating from control theory, observability is the ability to determine the internal state of a system based on the data it generates. Observability tools are all around us – car dashboards display fuel levels and engine RPM; airplane cockpits display air speed and cabin temperature. We even have server infrastructure tools that display logs, metrics, and traces to help us understand the web services they monitor.
In the context of robotics, observability helps us understand sensor inputs, planned trajectories, and control outputs. But observing robots at scale is no simple feat: robotics data is incredibly complex. It includes multimodal sensor data like images, point clouds, and GPS data. It includes semantic data like joint states, pose, and behavior trees. And it is collected by many devices across many locations, often under connectivity-constrained conditions.

Image courtesy of Third Wave Automation.
Existing developer tools struggle to meet these realities. Traditional robotics tools like RViz and RQt are great for developing prototypes, but they struggle with cloud workflows, data discovery, or team collaboration. Server observability tools are more mature, but these fall short when handling multimodal data like images, maps, and 3D data.
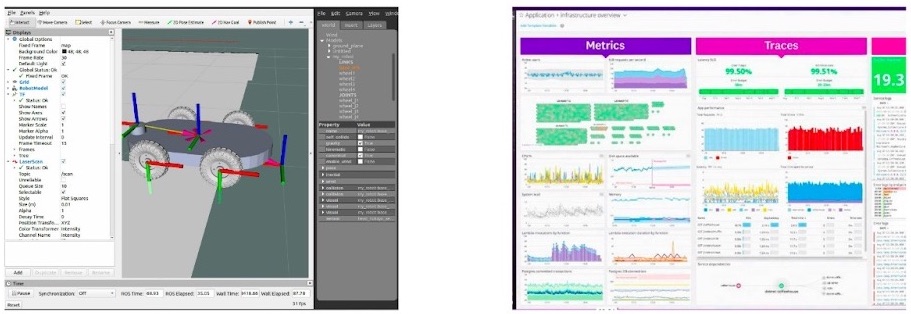
We need purpose-built tools to tackle the unique observability challenges of robotics development.
The four pillars of observability
There are four essential pillars of a robust robotics observability stack – recording, uploading, processing, and analyzing data. A well-executed observability strategy built on these pillars will vastly accelerate development and simplify scaling.
Recording
Standardized logging will pay dividends throughout your development lifecycle – it simplifies downstream processing, streamlines visualization and debugging with tools like Foxglove, and facilitates collaboration across teams.
Most robotics data can be broken down into three broad categories: lightweight telemetry (e.g. robot pose and system state, useful for business insights and analytics), downsampled sensor data (e.g. lower resolution or reduced frame rate data, useful for triaging incidents), and full-resolution data (e.g. raw camera and lidar, required for frame-by-frame debugging and AI training). Depending on how you decide to split files while recording, if at all – either by time (e.g. every minute), type (e.g. telemetry data in one file, sensor data in another), or topics – you can simplify how you access and transport this data later.
Regardless of what type of data you’re recording, we recommend using a standardized format like ROS bag or MCAP. These formats combine multimodal data streams into a single self-contained file and help you avoid the “junk drawer” approach to data management – where different categories of data encoded in different formats live in different places on your robot.
Uploading
Streamlining how you get data off robots and into the cloud is critical to a seamless development process.
Bandwidth is always a limiting factor in robotics. Many robots are capable of logging over a gigabit per second, but might be lucky to share a 100 Mbps internet connection per site. Agricultural robots are lucky if they have internet at all. Whatever the case may be, it’s critical to plan around these constraints. Are your bandwidth limits specific to a site, a robot, or certain times of the day? Do you have data caps or price constraints? These questions can help determine how much bandwidth you need, how much of your data is worth uploading over the network, and how much overhead to reserve for operations like remote assistance and teleoperation.
With Foxglove’s robot agent and edge sites, you can remotely import edge recordings to the cloud with a single click.
Processing
There are several reasons you may want to post-process robotics data in the cloud. If you’re using proprietary messages, you may want to transform them into standardized schemas for third-party visualization. If you want to train or evaluate AI models, you can add ground-truth labels to data or run it through simulation tests. If you want to feed data into third-party systems like data warehouses or time series databases, you may want to enable ETL (extract, transform, load) workflows in the cloud.
Whatever the use case, you can use the Foxglove API to track your data flow, and webhooks to trigger post-processing steps and notifications.
Analyzing
To improve your robots’ performance, you must be able to replay multimodal data – both from a high-level view (across days of recording) and at the micro level (for frame-by-frame debugging). Using Foxglove to stream data from the cloud can empower everyone on your team - from engineers to operations and product managers - to visualize and debug data themselves.
In addition to playback, finding and annotating events of interest is critical for more detailed incident triage. Foxglove provides events to facilitate team-wide insight into why your robots are acting the way they are.
Stay tuned
Until recently, getting a robot to execute tasks in a lab was the primary goal for many robotics developers. But one working robot does not guarantee commercial success – it’s simply the starting line for bringing products to market.
As robots continue to show up in our daily lives, we need to fundamentally change how we build them – that is, with an end-to-end observability strategy. By focusing on how we record, upload, process, and analyze data, we can take prototypes to market and integrate them into the real world – keeping robotics reliable, commercially viable, and safe for everyone to enjoy.
To see how Foxglove can help your robotics organization integrate observability at every phase of development, you can schedule a demo with the Foxglove team or contact us with specific questions and concerns.


