Recording Your Robotics Data
Trade-offs to consider when collecting data for analysis
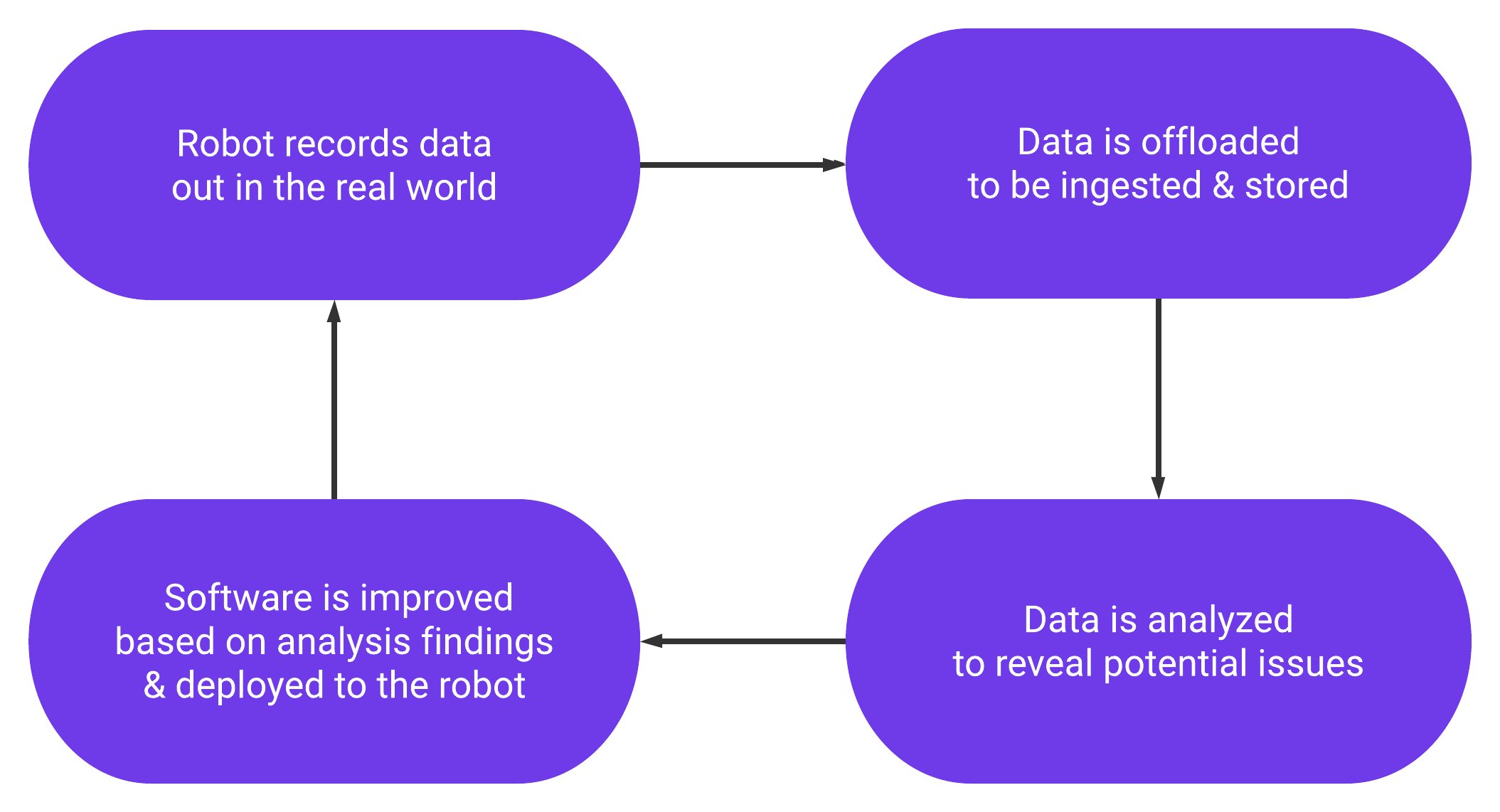

The typical cycle for robotics development usually starts with a deployed robot collecting data on a real-world excursion – whether that world is a warehouse, a public road, or the ocean’s “twilight zone”.
Typically, this data is offloaded into storage at the end of the excursion, and then analyzed to determine the improvements the robot’s software requires. The necessary changes are made, the new and improved software is deployed onto the robot, and that robot is sent back out into the world to collect more data.
And so the cycle continues.
In the robotics community, there is no shortage of tools that can help you inspect, analyze, and visualize your data. From native Robot Operating System (ROS) tools like rqt and rviz, to newer generations of tools like PlotJuggler and Foxglove, there are a multitude of ways you can inspect the inner workings of your robot’s brain.
But how do you get to a point where you have robotics data to visualize in the first place? What technical decisions do you need to make, and what steps do you need to take, to collect your data? How do you weigh all the possible strategies for this vital step?
Though there isn’t an industry-wide standard or one right answer, there are basic trade-offs to consider when deciding how to collect your robotics data. The decisions you make will depend on your project’s specific goals and constraints. By having a list of options to weigh, you can make more informed choices about the best data strategy for your project.
Data collection approaches
Before you can store or analyze any data, you need to collect it. There are several ways you can do this:
- Local disk recording
- Live telemetry
- Hybrid approach
All these methods have their pros and cons – the frequency with which your robot needs to send real-time data, the volume of data it records on a typical excursion, and its offload bandwidth will all inform which method you should use.
Your guiding principle should be finding the strategy that will most consistently return uncompromised data from the dynamic real-world environments that your robot navigates. Your data will guide future iterations of your robot, so the method that allows you to collect and learn from your data most reliably is often a good place to start.
Local disk recording
Robots are often deployed to areas that are inconvenient or dangerous for humans to go, and consequently cannot rely on a consistent internet connection to safely offload data. These robots with inconsistent or limited in-the-field connectivity can write their data to local storage to ensure that it can be collected and retrieved properly.

Your robot’s disk space will also affect how you collect data. With limited space, your robot must be more discerning about what data to record and what data to throw away. Running more business logic on the robot itself will conserve disk space – in this scenario, only the lighter-weight derived insights would be recorded to disk. While this “stretches out” disk space by writing a “lower resolution” version of your data, processing raw data live on your device will impact your robot’s real-time performance.
Finally, the importance of real-time feedback will determine how you record your data. If your data does not need to be referenced until the robot is back from the field, purely local disk recording is ideal. However, if you need to monitor your robots in real-time, local disk recording would not be able to address this requirement.
Live telemetry
If it is crucial for you to know at any given time where your robot is, your robot must be able to offload data to a storage solution – like the cloud or your laptop – as it actively collecting it.

Unlike local disk recording, which is blissfully independent of an internet connection, real-time offload requires a consistent and reliable connection to your robot – either wirelessly or via a physical cable. Since network connections can be unreliable, your robot can use in-memory buffering to avoid losing vital data whenever connectivity drops, transmitting these stored messages once a stable connection returns.
Due to bandwidth constraints, live telemetry is usually reserved for a small subset of your data. However, real-time offload of full-resolution data can be particularly useful in controlled scenarios, when your internet connection is reliable or when the scope of your task is within certain limits – for example, when you are conducting a sanity check on your robot or calibrating its sensors at homebase before sending it off into the field.
Hybrid approach
Both local disk recording and live telemetry can be present at once on a given robot – some data can be analyzed asynchronously after the robot has returned, and other data can be immediately transmitted for real-time monitoring.
Given that these approaches are useful in different scenarios, you can mix and match local disk recording and live telemetry for subsets of your robotics data. Ultimately, the environment that your robot navigates, the type of data it wants to collect, and its goals while out in the field will all determine how you record your data.
A hybrid approach is especially useful when you want both real-time insight into your fleet and high resolution data to diagnose potential failures. With live telemetry, you can monitor your fleet’s location and current status. In the event of a failure, you can upload the full fidelity data recorded on the robot’s local hard disk to review it for diagnosis. In short, the hybrid approach navigates the trade-off between how much local disk space you have (local disk recording), and how much data you can reliably offload via your available bandwidth (live telemetry).
Recording formats
Knowing how to record your robotics data is only half the battle. Another equally important question to address is the format in which to record this data.
There are several main criteria to consider when weighing data format options. Namely, you will want to choose a format that makes your data:
- Conducive to analysis
- Trivial to recover in case of hardware or software failure
- Possible to record with low overhead
- Easy to offload
- Self-describing
Different data formats facilitate different types of analysis. Choose a format while keeping in mind the type of analysis you may want to perform – whether it’s visually playing back a recorded session, or using SQL to query petabytes of recordings.
Your data should be stored in a format that makes it easy to recover. For example, in the event of an unexpected shutdown or accident, the data your robot has already recorded should be preserved and remain uncompromised.
Your robot’s recording process should be IO and CPU efficient. The volume of data you write and its compressibility will all affect performance and offloading.
Finally, your data should contain self-describing schemas for easier deserialization and compression. This enables you to decode your data without having to reference separate interface definition files, which may change frequently.
In short, choose the data format that allows your robot to record and offload its data for future analysis – all within its performance and bandwidth constraints. Let’s cover your options, based on your robotics framework.
ROS 1 robots
ROS is currently the industry standard for robotics data recording, mainly because it allows you to get up and running quickly, and easily integrate features that would be very time and labor-intensive to build yourself – i.e. modules for computer vision, SLAM, etc. This allows you to leverage the expertise of your peers, and makes collaborative robotics development extremely easy.
ROS allows you to write the messages published by your nodes throughout the course of a robot’s excursion to a bag file. Bag files store ROS messages in a format that can then be played back, visualized, and analyzed – along with message definitions for all these messages. Many tools like rqt_bag and rosbag have been written to help you record, play back, and otherwise interact with these bag files. Writing your data to bag files optimizes recording and playback performance, because you avoid deserializing and reserializing your messages.
ROS 2 robots
Whereas ROS 1 is a bundle of data formats, transport protocols, and reference implementations (C++ and Python), ROS 2 is a more generic C API with pluggable implementations. Even though ROS 2 has a default network transport protocol (DDS) and a default bag storage implementation (sqlite3), ROS 2 functions less as specific implementations and more as an abstract middleware interface for serialization, transport, and discovery. As such, rosbag2 allows recording and replaying of different data formats via a flexible interface, improving communication over different networks.
While ROS 2 seems like a promising new direction for ROS, there are a few in-progress issues that could pose a problem to recording and playback. Most notably, ROS 2 bags currently do not store message definitions alongside their recorded data. This omission makes it more difficult for external tools like Foxglove to inspect and analyze this data. With that said, storing message definitions in ROS 2 bags is an open issue that the rosbag2 team is actively tracking.
Non-ROS robots
Outside of the ROS ecosystem, there are no clear-cut standards for data serialization formats.
Some teams use an open source data serialization format like Apache Avro, which optimizes for space and performance by storing data in compact binary format. Avro files are easy to process and read, because they store their schemas in JSON format. While JSON alone would get unwieldy for repeated fields across records, AVRO files use a direct mapping that makes it efficient for higher volume usage.
Other teams record a raw stream of Protobuf messages to a file. Protobuf, Google’s mechanism for serializing structured data, transmits data as a compressed binary to conserve space, bandwidth, and CPU usage. Because there isn’t a storage protocol, you will have to do some upfront work to get started. You can use length-delimited streams to distinguish between subsequent messages, and design your own container format to provide message definitions for your data stream.
It is not uncommon for non-ROS teams to convert their data in custom recording formats into bag files, so they can load their data with ROS analysis tools.
Summary
There are many tradeoffs to consider before your robot even starts collecting data. What we covered is not a one-size-fits-all approach, nor is it an exhaustive list of all the ways you can optimize data collection. Knowing your robot’s working environment, your constraints, and your data’s usage is paramount to assessing how you should tackle these questions.


