Legged robots are redefining the boundaries of robotic mobility. Today, these systems can navigate environments that were previously off-limits, from the rubble of demolished buildings and dense forests to the depths of unexplored caves. To push these capabilities even further, we are introducing GrandTour: a large-scale, open-access legged-robotics dataset. Our goal is to provide a comprehensive suite of multi-modal sensor data to accelerate the development and benchmarking of autonomy algorithms. By providing high-quality data, we aim to guide the development of entirely new applications for legged systems in the field.
ANYmal with Boxi payload traversing forest path. Source: Robotic Systems Lab, ETH Zurich
The dataset spans more than 49 missions across indoor, urban, industrial, and natural environments, including day and night operations and challenging weather and visibility conditions. Beyond the data itself, GrandTour aims to make real-world, out-of-distribution robotic data more accessible to the machine learning, computer vision, and robotics communities alike.
In addition to serving as a dataset release, GrandTour also serves as a benchmark for evaluating localization and perception methods in realistic field conditions. Its broader goal is to support the development of more robust multimodal systems that can operate reliably outside controlled laboratory settings. As part of its mission, GrandTour will continue to expand, incorporating additional environments with different robots.
Sensor Stack

GrandTour platform components
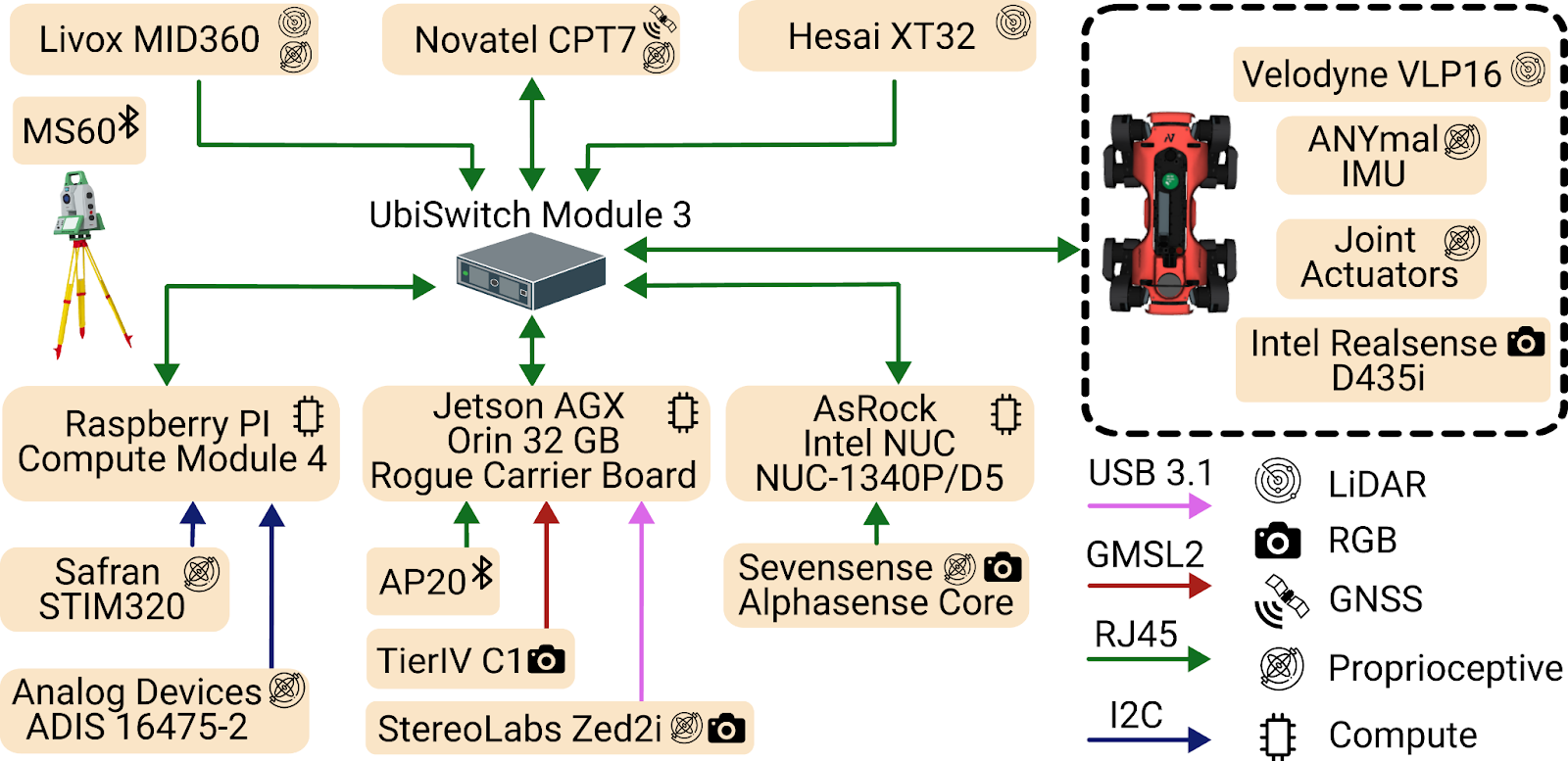
GrandTour is built around a deliberately diverse and redundant sensor suite. Rather than depending on a single sensing modality, the platform combines complementary sensors for geometry, vision, inertial estimation, proprioception, and global referencing. These sensors span across our integrated sensor suite, Boxi, and the ANYbotics ANYmal-D quadruped base platform.
For LiDAR sensing, the platform includes a Livox Mid-360 for near-field 3D structure, a Hesai XT-32 for longer-range perception, and a Velodyne VLP-16 on ANYmal. This combination gives strong geometric coverage across both local and more distant structures.
For vision, Boxi integrates five Sevensense CoreResearch global-shutter cameras, three Tier IV C1 HDR rolling-shutter cameras, and a ZED2i stereo camera. ANYmal contributes six Intel RealSense D435i depth cameras. Together, these provide overlapping coverage across monocular, stereo, HDR, and depth-based perception.
For inertial sensing, the platform includes multiple IMUs with different performance characteristics, ranging from lower-cost MEMS devices to a higher-grade Honeywell HG4930. ANYmal also contributes its own onboard IMU. This makes the platform useful not only for state estimation, but also for studying the effect of IMU quality on downstream localization performance.
For global reference and ground truth, the system uses a dual-antenna NovAtel CPT7 RTK-GNSS setup together with a Leica total-station-based positioning pipeline. These measurements are combined to generate accurate 6-DoF ground-truth trajectories, even in challenging outdoor environments where pure satellite-based positioning or pure local sensing would be insufficient on their own.
In addition to exteroceptive and inertial sensing, the dataset includes joint encoders, commanded motion, contact-related robot-state information, motion-compensated LiDAR point clouds, and post-processed INS trajectories. This makes the dataset particularly interesting for researchers working on SLAM, legged state estimation, multi-modal fusion, perception-aware locomotion, and navigation.
Lessons Learned
A fundamental learning is that the design and development of a multimodal payload requires joint optimization of hardware and software. This became apparent to us when we realized that our Ethernet switch is a non-PTP switch, implying that microsecond-level line delays might occur. While this wasn’t a blocker for the project, it is important to note that similar considerations must be taken from a sensor’s claimed functionality to whether an IMU has a C-level driver available.
GrandTour also showed that there is no universally best sensing modality. In practice, LiDAR- and GNSS-based estimation were generally more reliable than camera-only or kinematics-based approaches, but performance still depended strongly on the environment. Open spaces, weak visual texture, smoke, changing lighting, and GNSS-denied areas all changed which modalities were most useful.
Another important lesson is that seemingly small hardware substitutions matter. Replacing a higher-quality long-range LiDAR with a lighter, cheaper alternative reduced performance, especially in more challenging scenes. The same held for cameras: global-shutter configurations proved more reliable for visual localization than rolling-shutter configurations. These trade-offs clearly translate into estimator performance, not just into hardware specifications.
GrandTour also reinforced that IMU quality matters most when external correction becomes weak or unavailable. In tightly coupled LiDAR-inertial pipelines, higher-grade IMUs did not always produce large gains during normal operation, but they were clearly more robust during dead reckoning and measurement dropouts.
A particularly important lesson was that the validation of the claimed synchronization, calibration, and ground truthing accuracy must be impeccable. Many public datasets underestimate this single point in the name of completing their projects and end up with overpromised claims. Hence, why GrandTour took 2 years to realize.
Finally, GrandTour showed that robust robotics performance comes from disciplined full-system integration. Good results depend not only on the individual sensors, but on how sensing, compute, networking, timing, and mechanics are designed together. The strongest takeaway is simple: reliable field performance is built at the system level, not added afterward.
Architecture
GrandTour Architecture
The GrandTour platform can be separated into two tightly coupled parts: our custom multi-modal sensory payload, Boxi, and an ANYbotics ANYmal quadruped robot as the carrier platform.
Boxi is a compact, mechanically rigid payload designed to carry a diverse sensor suite while maintaining calibration consistency and reliable data capture in the field. Boxi contains three compute modules: an NVIDIA Jetson AGX Orin, an Intel NUC, and a Raspberry Pi Compute Module 4. Each module is responsible for a subset of the sensor suite. This division is important because camera pipelines benefit from stronger onboard compute, while IMUs and LiDARs can run efficiently on CPU-based systems. At the core of the system is the UbiSwitch Module 3 Ethernet switch, which enables TCP/IP communication between sensors and compute modules. In practice, this means we avoid unnecessary cross-device communication during recording and focus instead on accurate time synchronization, adequate system integration, and utilities for resilient data recording.
In addition to the main compute modules, Boxi also includes a custom Leica Geosystems AP20 and a NovAtel CPT7 INS/GNSS unit, which form the foundation of our ground-truth generation pipeline. These are industrial solutions that help GrandTour achieve adequately synchronized, accurate ground-truth positioning.
A particularly important aspect of the architecture is timing and synchronization. CPT7 is the time grandmaster, provides GNSS time if available, otherwise a local-time approximation. Jetson within Boxi IEEE 1588v2 PTP synchronizes to it; the other modules, NUC and Raspberry Pi, synchronize to the Jetson again through the PTP. On the other hand, the main compute module of ANYmal synchronizes with the Jetson on Boxi via the NTP protocol.
During deployment, each compute module, including those on ANYmal, records locally to avoid unnecessary network traffic and reduce the risk of data loss. This design choice improves robustness during long and demanding field missions.
Recording Structure
One of the major design questions we had to answer early on was: how would we handle all this data, both during recording and in post-processing?
This led us toward a divide-and-conquer strategy. We chose to split the recorded data primarily by sensor stream and, in our internal workflow, also by time. Using time as an additional division parameter makes the number of file divisions more consistent across sensors, helping operators quickly identify anomalies without having to compare file sizes across different data types and rates.
We are very happy with this decision. The biggest advantage is modularity. It allows us to inspect, validate, and process sensor streams independently, making it easier to write dedicated post-processing tools for each sensor or modality. This also aligns well with the public dataset philosophy, where users can access the specific streams they need rather than being forced to handle very large, monolithic recordings. Considering the suite can generate more than 1 GB/s of data, these points become even more important.
The main downside is a small amount of post-processing overhead. Split recordings often need to be merged, synchronized, or jointly indexed before downstream processing. However, in practice, we found that this overhead is outweighed by the gains in robustness, interpretability, and processing flexibility.
GrandTour as a Foxglove Example Dataset
With the release of this blog post, a section of a single GrandTour recording is available early to anyone with a Foxglove account. You will always find it in the example datasets.
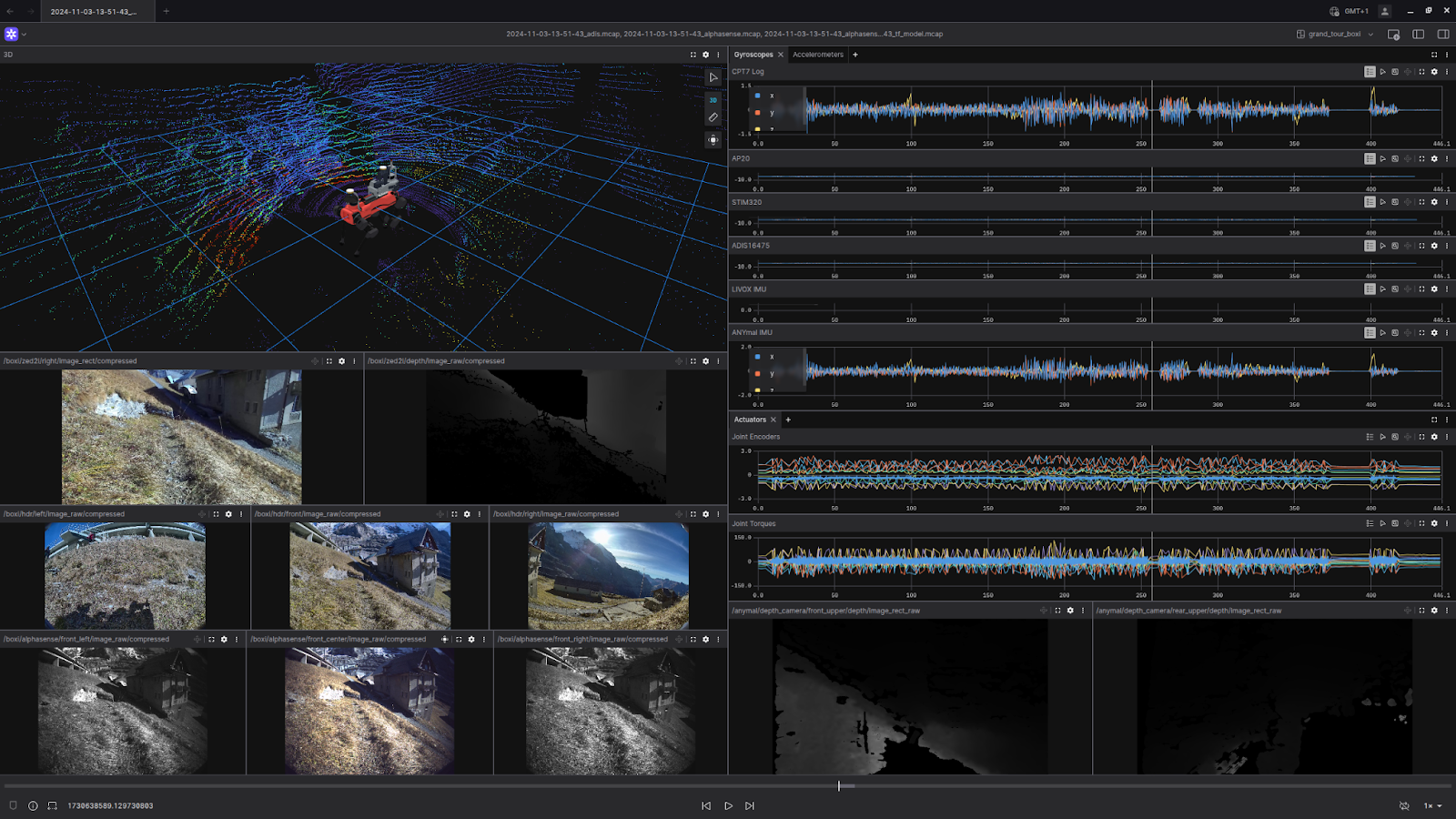
GrandTour dataset visualized in Foxglove
Future outlook of GrandTour
We have already collected an additional 15 sequences across 3 countries as part of our extension efforts. Including some new sequences with the Radar modality. GrandTour is a multi-year project in which, with different collaborators, we are expanding our outreach and demonstrating that legged-robotic data is vital for training fine-tuned spatial AI models.
We are also improving our SW/HW stack, particularly the sensor suite and the post-processing software. We are eager to hear from any collaborators with interesting environments and funding opportunities where we can join them to collect further data.
About the Authors
Turcan Tuna is a Ph.D. candidate at ETH Zurich’s Robotic Systems Lab, where he works on robust spatial 3D perception and state estimation for robot autonomy in challenging real-world environments. His research focuses on robust localization and spatial 3D perception in perceptually degraded environments using optimization and data-driven methods. Website: https://www.turcantuna.com/
Jonas Frey is a Postdoctoral Researcher at Stanford’s Autonomous Systems Lab, where he works with Prof. Marco Pavone, and at UC Berkeley’s Berkeley Artificial Intelligence Research (BAIR), where he works with Prof. Jitendra Malik. His research focuses on learning-based perception and navigation for legged robots, with particular emphasis on reinforcement learning policies and Large Behaviour Models. Website: https://jonasfrey96.github.io/
Citation and Sources
Please cite the following works if you use this dataset.
Journal Publication pre-print (Under-review for Sage IJRR) (arXiv) GrandTour: A Legged Robotics Dataset in the Wild for Multi-Modal Perception and State Estimation https://arxiv.org/abs/2602.18164
Turcan Tuna* and Jonas Frey* (*equal contribution), Frank Fu, Katharine Patterson, Tianao Xu, Cesar Cadena, Maurice Fallon, and Marco Hutter
Payload Publication (RSS) Boxi: Design Decisions in the Context of Algorithmic Performance for Robotics https://www.roboticsproceedings.org/rss21/p134.html
Jonas Frey*, Turcan Tuna*, Lanke Frank Tarimo Fu* (*equal contribution), Cedric Weibel, Katharine Patterson, Benjamin Krummenacher, Matthias Müller, Julian Nubert, Maurice Fallon, Cesar Cadena, Marco Hutter